Part 1 – the Stacks
AppSync
I’ve been hearing some seemingly far fetched claims about AppSync recently. Namely that it was both easy and
quick to set up and then “you hardly need to touch it”. Basically an instant API just add schema proposition, so I
thought I’d test the theory and see how close we could get to that ideal.
AppSync is a serverless GraphQL API technology so if you were after a Rest API and nothing else will do you’re out of
luck already. It’s also possible to host a serverless GraphQL API on AWS using ApiGateway with a Lambda
used to marshal the GraphQL sources. AppSync however can be used without the need for an extra
Lambda using RDS resolvers to house the queries that back up the GraphQL schema. That said it can use a Lambda or pretty
much anything all at the same time according to AWS…
“Interact with multiple data sources (SQL, NoSQL, search data, REST endpoints, and microservices) with a single
network call.”
Obviously that’s great but let’s just try and connect with a single SQL db and see how easy that is
AppSync is easy to set up in the AWS web console in fact if you have an RDS instance with some tables in you can just
use a wizard on the console and it sets the lot up for you. To be fair there’s very little fine grained control and you’re
probably not going to want to set up APIs across multiple environments by logging on to each and using a wizard. So we
need some infrastructure as code and it’ll come as no surprise to anyone who’s read the title of the blog that I’m going to use the CDK
the CDK
According to the docs the CDK supports “TypeScript, Python, Java, .NET, and Go (in Developer Preview)”. I’m using Java
If you want to do the CDK in the JVM space then AWS only supports code written in Java using maven
as the build tool. But that doesn’t mean you can’t use Kotlin and gradle which is exactly what I did on my next
experiment after this. Hopefully I’ll get time to write that up at some point in a future blog.
Getting Started
I’m not sure how useful the AWS docs are for getting started with the CDK
but follow the link and have a read by all means, all I really had to do was install CDK before I got started
npm install -g aws-cdk
Apps & Stacks
To start off with you’ll need a main class to house your app in
public class GraphQLApp {
public static void main(final String[] args) {
App app = new App();
You then set up the environment and add stacks to the app
Environment environment = Environment.builder()
.account(System.getenv("CDK_DEFAULT_ACCOUNT"))
.region(System.getenv("CDK_DEFAULT_REGION"))
.build();
VPCStack vpcStack = new VPCStack(app, prefix + "graphql-vpc-stack",
StackProps.builder()
.env(environment)
.build());
DatabaseStack databaseStack = new DatabaseStack(app, prefix + "database-stack", DatabaseStack.DatabaseStackProps.builder()
.env(environment)
.prefix(prefix)
.vpc(vpcStack.getVpc())
.build());
SqlLambdaStack sqlLambdaStack = new SqlLambdaStack(app, prefix + "sqk-lambda-stack", SqlLambdaStack.SqlLambdaStackProps.builder()
.env(environment)
.prefix(prefix)
.vpc(vpcStack.getVpc())
.cluster(databaseStack.getCluster())
.rdsSecret(databaseStack.getRdsSecret())
.dbName(databaseStack.getDbName())
.build());
new AppSyncStack(app, prefix + "app-sync-stack", AppSyncStack.AppSyncStackProps.builder()
.env(environment)
.prefix(prefix)
.vpc(vpcStack.getVpc())
.cluster(databaseStack.getCluster())
.rdsSecret(databaseStack.getRdsSecret())
.dbName(databaseStack.getDbName())
.build());
As you can see I’ve got four stacks the VPCStack, DatabaseStack, SqlLambdaStack and AppSyncStack
VPC Stack
The VPC stack is really simple since it just contains the VPC
this.vpc = new Vpc(this, "TheVPC", VpcProps.builder()
.maxAzs(2)
.build());
The created VPC is then exposed back to the other stacks since we’ll need to reference
it in the other stacks.
@Getter
public class VPCStack extends Stack {
private final Vpc vpc;
Database Stack
The Database Stack sets up the cluster and the RDS secret used to connect.
rdsSecret = new Secret(this, secretId, SecretProps.builder()
.secretName(secretName)
.generateSecretString(SecretStringGenerator.builder()
.excludePunctuation(true)
.passwordLength(16)
.generateStringKey("password")
.secretStringTemplate("{"username": "" + dbUserName + ""}")
.build())
.build());
var engine = DatabaseClusterEngine.auroraPostgres (
AuroraPostgresClusterEngineProps.builder()
.version(AuroraPostgresEngineVersion.VER_13_12)
.build()
);
var group = new ParameterGroup(this, groupId,
ParameterGroupProps
.builder()
.engine(engine)
.build()
);
cluster = new ServerlessCluster(this, clusterId, ServerlessClusterProps.builder()
.engine(engine)
.parameterGroup(group)
.vpc(props.getVpc())
.vpcSubnets(SubnetSelection.builder()
.subnetType(SubnetType.PRIVATE_WITH_EGRESS)
.build())
.defaultDatabaseName(dbName)
.credentials(Credentials.fromSecret(rdsSecret))
.build());
Once the cluster is set up we need to put some schema in the DB so the next stack to run
is the sql stack
SQL Lambda Stack
How do we do migrations in a serverless world? Before we could just use Flyway
or Liquibase to deploy them as the webserver we were hosting our microservice on
spin up. But we don’t have a webserver any more and we don’t want to add
to our lambda spin up times by checking for un-deployed migrations at the start of every lambda. Our AppSync API only
has resolvers so there’s not even a lambda start up to hook into.
Flyway –
I spent some time trying to get a flyway lambda to work and to some degree it did work but it was difficult to work with
and I realized that I could probably get closer to what I wanted using my own code.
The stack sets up a lambda function and an s3 bucket. Any file uploaded to the s3 bucket triggers the lambda which gets
each file from the bucket and runs all the file contents as sql. That’ll do for the minute since a full solution would be
a blog all by itself.
function = new Function(this, "SqlLambda", FunctionProps.builder()
.role(lambdaRole)
.memorySize(1024)
.vpc(props.getVpc())
.securityGroups(props.getCluster().getConnections().getSecurityGroups())
.runtime(Runtime.JAVA_11)
.environment(Map.of("RDS_SECRET", props.getRdsSecret().getSecretArn(),
"CLUSTER_ARN", props.getCluster().getClusterArn(),
"DATABASE_NAME", props.getDbName())
)
.code(Code.fromAsset("../sql-lambda/target/sql-lambda-0.0.1-SNAPSHOT.jar")) // the version number needs to be managed in the real world to ensure the redeploy of new versions
.handler("com.pennyhill.SqlLambdaHandler::handleRequest")
.timeout(Duration.seconds(140))
.build());
AppSync Stack
GraphqlApi api = new GraphqlApi(this, "AppSyncRDSResolver",
GraphqlApiProps.builder()
.name("AppsyncRDSResolverAPI")
.definition(Definition.fromFile("src/main/resources/schema.graphql"))
.authorizationConfig(AuthorizationConfig.builder()
.defaultAuthorization(AuthorizationMode.builder()
.authorizationType(AuthorizationType.API_KEY)
.apiKeyConfig(ApiKeyConfig.builder()
.expires(Expiration.after(Duration.days(365)))
.build())
.build())
.build())
.build());
RdsDataSource ds = api.addRdsDataSource("AuroraDS", cluster, rdsSecret, dbName);
Firstly we set up the GraphqlApi class and load in a schema defined in a
graphql file with the types defined in the graphql type language.
For example the getTicket query is set up in the query type like
type Query {
getTicket(id: ID!): Ticket
Then we set up the RDS resolvers for each query. Originally that looked a bit like this
repeated for each query or mutation
ds.createResolver(BaseResolverProps.builder()
.fieldName("getTicket")
.typeName("Query")
.requestMappingTemplate(MappingTemplate.fromString("{n" +
" "version": "2018-05-29",n" +
" "statements": [n" +
" "select * from tickets where id = '$ctx.args.id'"n" +
" ]n" +
"}"))
.responseMappingTemplate(MappingTemplate.fromString("#if($ctx.error)n" +
" $utils.error($ctx.error.message, $ctx.error.type)n" +
"#endn" +
"#set($output = $utils.rds.toJsonObject($ctx.result)[0])n" +
"#if ($output.isEmpty())n" +
" nulln" +
"#else n" +
" $utils.toJson($output[0])n" +
"#end"))
.build());
The response template is the same for everything so that becomes a constant. The request only
varies in the sql queries and whether we’re handling an id generation (for an insert) so that becomes a method and we get…
// Queries
BaseResolverProps.builder()
.fieldName("getTicketById")
.typeName("Query")
.requestMappingTemplate(MappingTemplate.fromString(requestTemplate(false, List.of(
"select * from tickets where id = '$ctx.args.id'" ))))
.responseMappingTemplate(MappingTemplate.fromString(RESPONSE_TEMPLATE))
.build()
Which isn’t perfect but does reduce the work for each query and make it more readable.
The resolvers are listed in a separate file and loaded into the stack from there
getResolverProps().forEach(
resolverProps -> ds.createResolver(props.getPrefix() + resolverProps.getFieldName() + resolverProps.getTypeName(), resolverProps)
);
So far so good…
We now have 3 areas where code changes happen because as we develop the app; the sql schema in the sql migrations,
the schema.graphql file we load into the AppSync stack and the resolvers we use to support the graphql schema. Generating
in the web console gives us the basic get one, get all, create and update options for each table in the sql schema
(that includes the every table and that may not be something we want). The aim at the start was to have something as
good as the web console wizard so we need to generate some code.
Part 2 – generate some code.
Schema changes
If you want to try the code out but would like to use your own schema you can make changes to the files in the sql-scripts
folder and then go through the following steps to generate the code for the changes you’ve made. If you’re happy to use
the existing schema go straight to the “Deploying the app” section.
introspection
First things first we need to be able to gather the metadata from the database and use that to inform the code we’re
generating. I did take a look at the options of just using the AWS introspection options that are basically the underpinnings
of the wizard we’re trying to emulate. After a few hours I’d really not got as much info as I would have by querying the
metadata of the datasource. Anyway I’m not sure generating the code on the fly as you deploy isn’t an anti-pattern. If we
generate from a local copy of the schema we would at least see what we’ve changed before we deploy it.
To generate the code we need a local copy of the database with the schema loaded into it. For this I’m using docker compose
and loading up the contents of the init.sql file in the sql-scripts folder. If you’ve made changes to the schema and
test-data folders in sql-scripts you’ll need to run generate-init-sql.sh in the sql-scripts folder. Once that’s done
you can start the local instance using
docker-compose up
Then just run the main file in the generate module and it’ll create a couple of files
in the infra module.
infra/src/main/java/com/pennyhill/gen/Resolvers.java
infra/src/main/resources/gen/schema.graphql
then back in the root directory run
npx graphql-schema-utilities -s "{infra/src/main/resources/gen/schema.graphql,infra/src/main/resources/*.graphql}"
-o "infra/src/main/resources/merged/schema.graphql"
this merges any existing schema with the generated schema. Change the AppSync stack to pull the definition from the merged
file
.definition(Definition.fromFile("src/main/resources/merged/schema.graphql"))
and the resolvers to load from both the generated and custom resolvers collections
getResolverProps().forEach(
resolverProps -> ds.createResolver(props.getPrefix() + resolverProps.getFieldName() + resolverProps.getTypeName(), resolverProps)
);
getCustomResolverProps().forEach(
resolverProps -> ds.createResolver(props.getPrefix() + resolverProps.getFieldName() + resolverProps.getTypeName(), resolverProps)
);
The generate module gets the metadata from the datasource and then uses some velocity templates to generate the files.
If you’re interested in the detail take a look at the code (see Useful links below)
Deploying the app
Now we have everything set up we just need to get it into our AWS account. Assuming your credentials are set up for the
cli in the normal way then run the deploy.sh file in the infra folder which will take a while and hopefully work 🙂
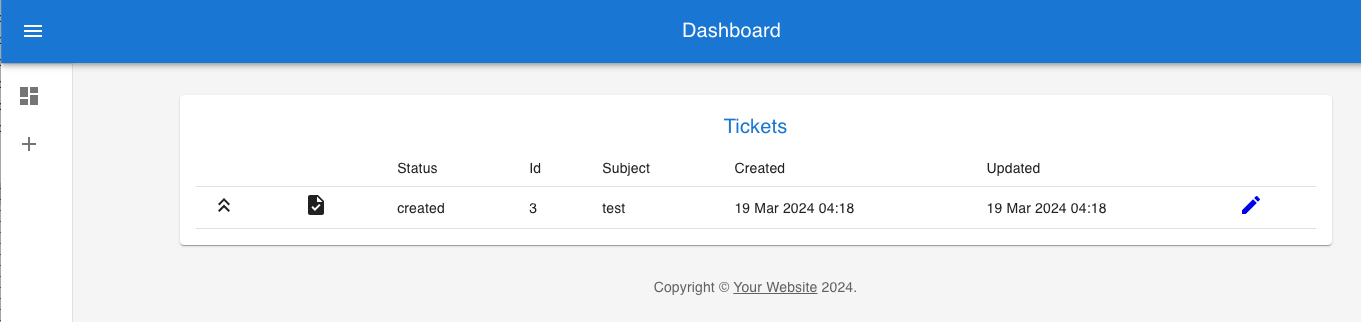
Once that’s done run the load-test-data.sh script in the sql-scripts folder to put some values in the tables. Then you
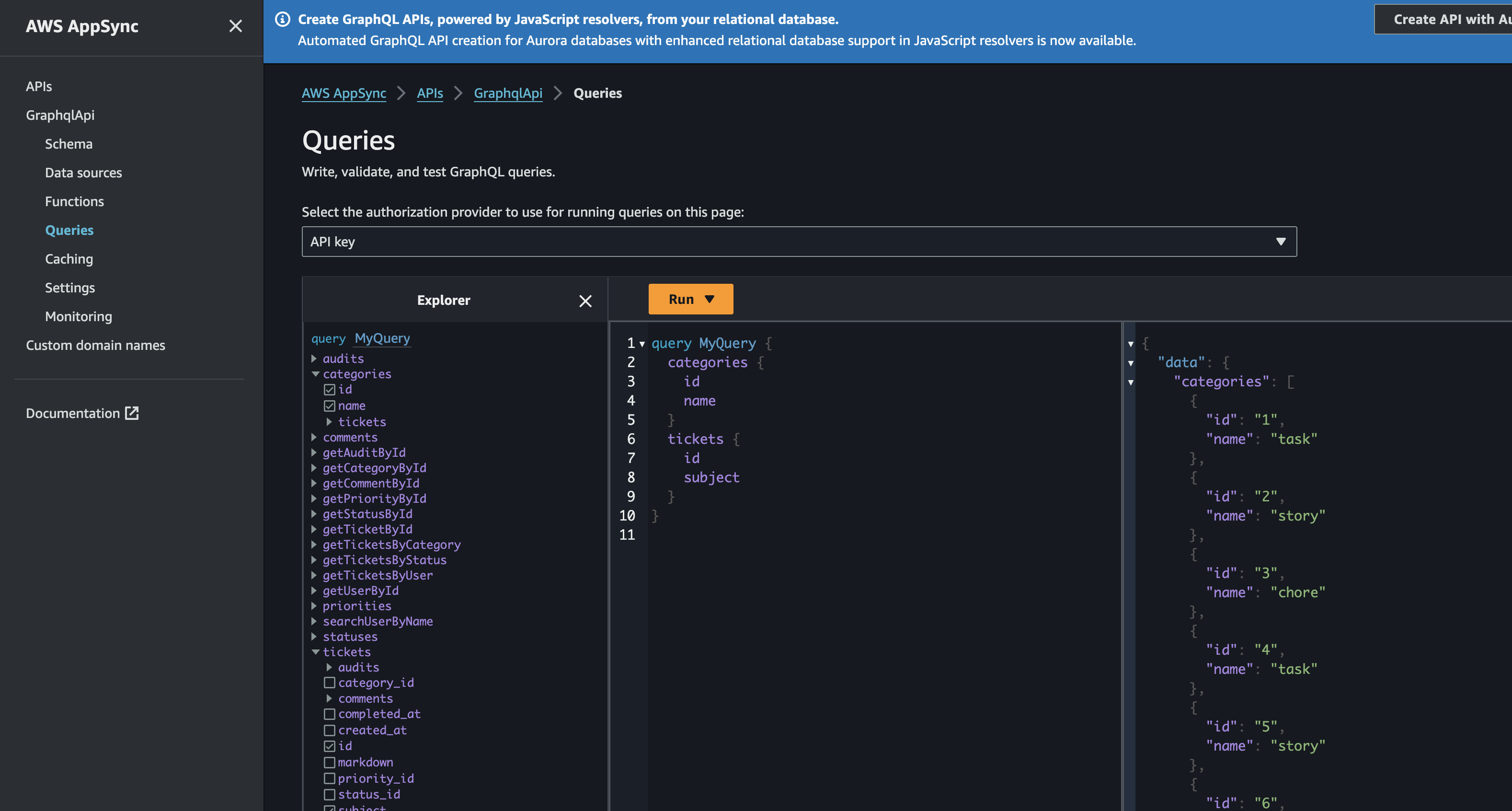
can go to the AppSync queries area to see some data.
Conclusion
Assuming it works that’s great as long as you have a sql schema you can go from there with relatively little effort to an API.
Also assuming that the SQL schema is a work in progress this can flex with those changes. What we’ve sacrificed for
expediency is any kind of local development and testing experience. This is a bit of a feature of serverless development
but particularly true of this since AppSync only supported by the pro version of localstack.
So without a generous benefactor handing out the pro licences we’re going to have to wait for each deployment to finish
before we can test in the AWS account. Maybe there’s a trade off because we’re potentially not going to need to make many
changes to the API, bit of a pain if that’s not the case though.
Where’s the tests?
There’s not many points in the code that we can do unit tests. The API is just an, albeit complex, infrastructure
definition. I think the only real way to test this is to check it’s all working in the environment. Ideally we’d have
automated testing and anything we’d generated would have test generated at the same time. If it’s a backend for a frontend
then you could run a full integration suite of tests using cypress or testcafe. Alternatively you could run junit tests
against the environment using the CICD tooling of your choice.
Going round the houses or round the bend?
The feedback loop for small changes is daunting. Write your code then wait many minutes for the changes to deploy then
see if it worked. That’s nothing like the kind of feedback we’re used to working on a local dev environment or using TDD.
I guess it’s the payment for getting up and running quickly but you could loose much of what you’ve gained by having longer
dev times for future changes.
Final thoughts on AppSync
It seems like a nice option if you’re fairly sure that all you have is a API exposing a database, for example a backend
for a frontend. The extended feedback loop and lack of opportunity for local testing would be a pain for anything more
complex. Though if your client/employer were supportive financially you could look into the pro localstack option.
What’s next
Now we have an api we can connect to it using AWS Amplify
you can go further and generate code for your UI (Web, IOS, Android).
Useful links
Github Project – the current state of the code
AWS CDK Examples – a AWS managed repo of CDK examples
Graphql CDK examples – AWS examples repo